- 音频采集播放
a. 采样率
b. 采样位宽
c. 声道 - 音频编解码
a. 码率
b. 编解码格式:Opus - 音频处理
a. 回声消除
b. 降噪
c. 自动增益控制
d. 混音 - 网络传输
a. 传输协议
b. 抗抖动
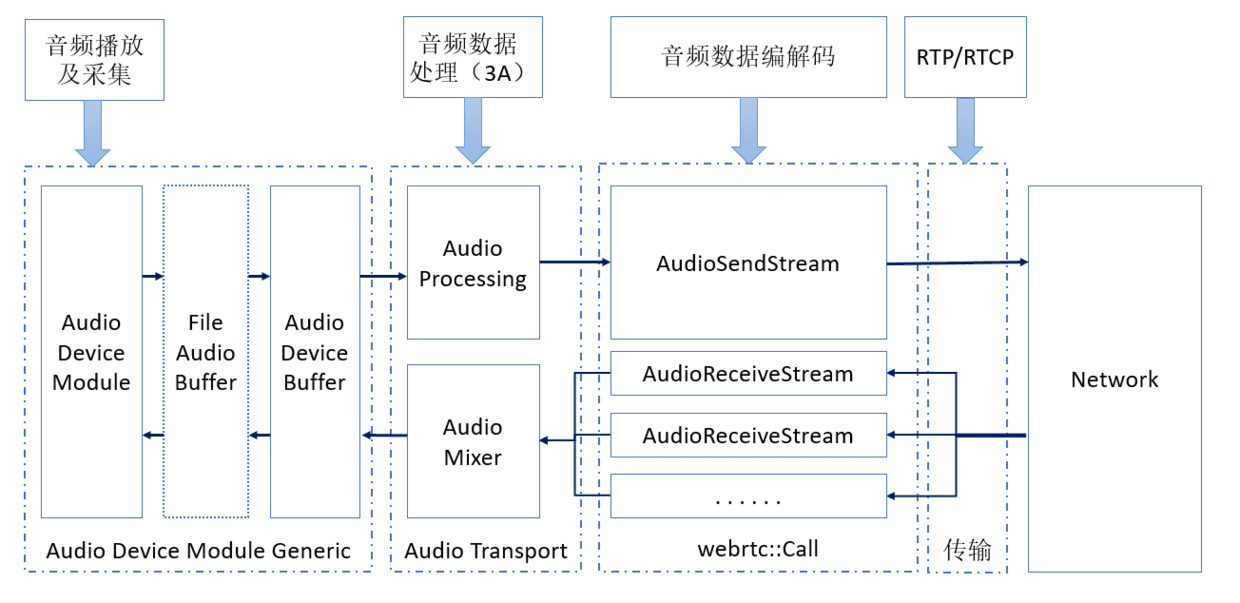
WebRTC由音频引擎、视频引擎和传输模块,音频处理在WebRTC占了很大一块,本文主要对WebRTC中涉及的音频处理进行简单介绍,不会对具体的实现进行介绍。上图是WebRTC中音频处理的流水线(上面的图是网上的图,如有侵权,通知即删),可以看出主要包含了音频采集播放、音频处理、音频编解码和音频传输。下面对这些模块逐一进行介绍。
音频采集播放
自然界的声音,包括人说出来的声音,都是模拟信号,这些模拟信号是不能被计算机存储和识别的,也不能通过网络进行传输。音频采集就是声音从模拟信号转换成数字信号的过程,而音频播放就是声音从数字信号转换成模拟信号的过程。对于音频数字信号来说有以下几个最主要的参数:
采样率
采样率是指录音设备在一秒钟内对声音信号的采样次数,单位是Hz,采样频率越高,声音的还原度越真实越自然。但是人耳可以听到的频度范围是20Hz~20000Hz,然后根据采样定理,也就是说最低只需要40kHz采样率就可以满足人耳的需求了,因此CD音质和音乐音频都是44.1kHz。但是采样率越高意味着数据量越大,因此在一些特殊的场景会使用更低的采样率,如语音通话场景,因为人声都是低于4kHz,因此在语音通话场景更多会使用8kHz或者16kHz的采样率。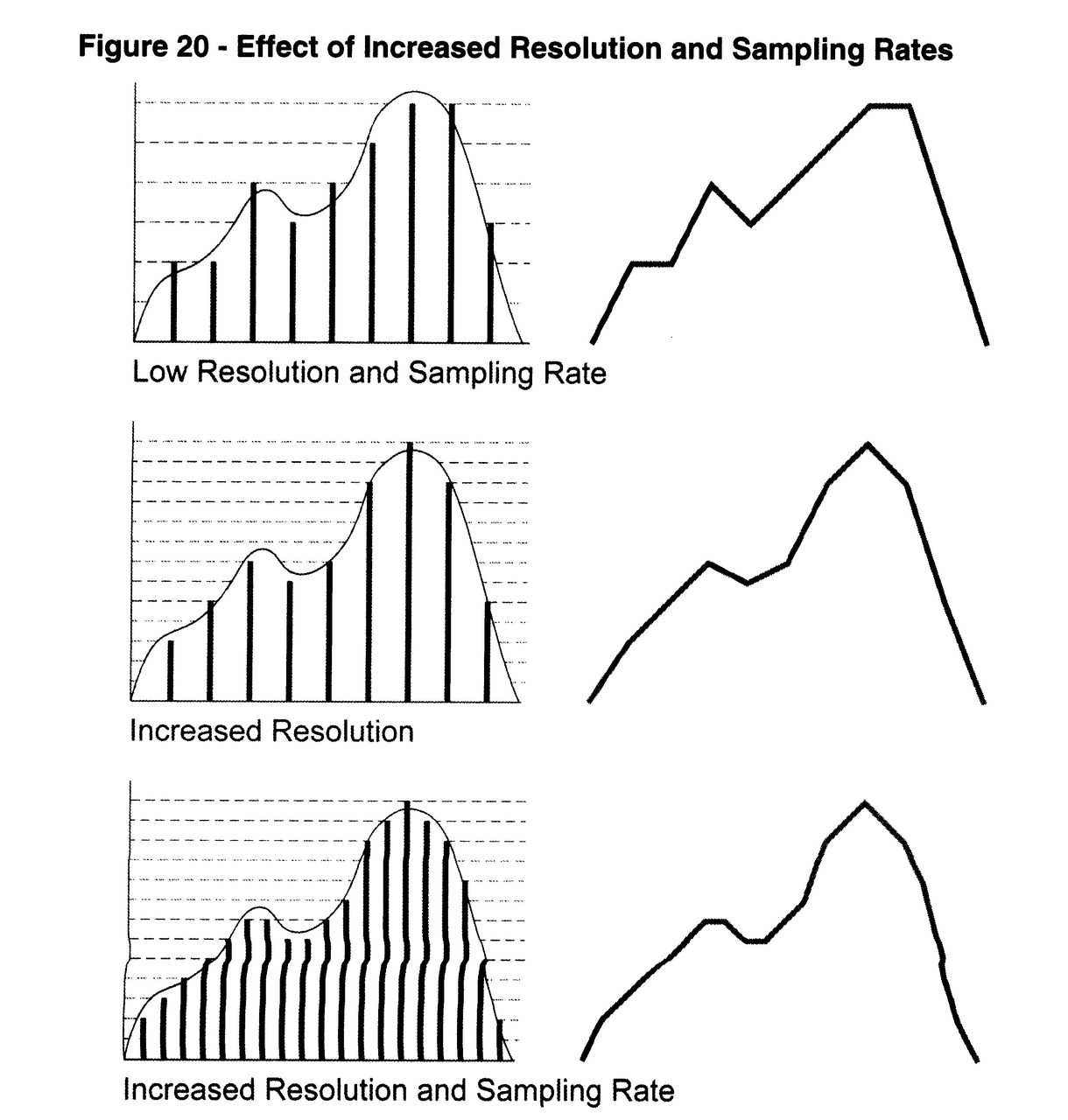
采样位宽
声音模拟信号经过采样后得一个个样点的值,这个值需要存储到计算机中,那么使用多少位数来表示这个 就是采样位宽,通常使用最多的是16bit,正好就是一个short类型。声道数
在使用录音设备进行声音采集时,只能表示到采集点处的声音信号,但是实际声音是有空间信息,为了表达声音的空间信息,就有了声道的概念。这里最有名的可能就是杜比全景声了,大家在电影院看电影的时候,感受到的被声音包围的真实感就是多声道的功劳了,当然这里并不是加多几个通道这么简单啦。
音频编解码
虽然音频的数据量没有视频的量那么大,但是如果直接传输原始的音频数据(原始的音频数据有个名字叫Pulse Code Modulation (PCM)),数据量也是挺大的。现在我们来计算下1秒采样率为48kHz双通道的音频信号的数据量有多大,1秒 * 48000个采样点 * 2个声道 * 每个样点2Bytes,这样1秒的数据量是192kB字节。这样的数据量在互联网发展的早期也是不可以接受的,这时候就需要音频编解码。简单的说,音频编解码就是利用人耳的心理声学特性将也一些不影响听觉的信号丢弃,从而减少信号量的方法,在WebRTC中用得最多的是Opus格式。对于音频编码器来说一个很重要的参数是码率,单位是kbps,即每秒的音频使用多少bits位来表示。音频编解码是音频领域一个很专业的领域,这里就不展开了。
音频处理
在实时通话场景,需要面对各种复杂的环境,处理各种音频问题,最常见的如噪声、回声、声音过大过小等,WebRTC中有一个专门的音频处理模块来处理这些问题,下面就简单介绍下这些模块。
回声消除(Acoustic Echo Cancellation)
实际通话场景是一个全双工通信系统非容易产生回声,如下图所示,远端说话声==》近端扬声器播放==》近端麦克风录制==》通过网络传输到远端的扬声器播放,经过这样一个音频环路后,远端又在扬声器里听到自己的声音,也就是回声,如果回声的延时很低时还会产生啸叫,这样是很影响通话体验的。这时就需要回声消除AEC模块了,通常录音数据都会先经过个模块,在传输前先把远端播放的数据消除,这样远端在播放的时候就不会听到回声了。回声消除AEC详细的原理介绍留到后面再介绍,这里先挖个坑。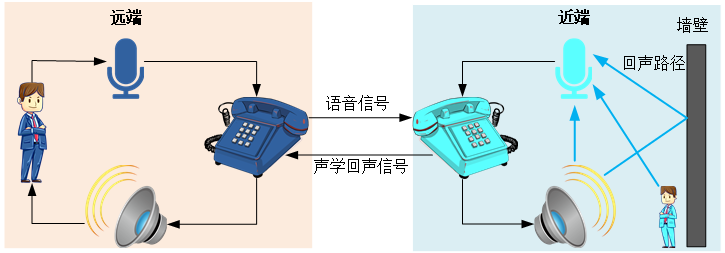
噪声抑制(Noise Suppression)
噪声抑制NS这个很好理解,实际的通话场景都会存在各种各样的噪声,为了保证通话体验不受影响,这时就需要噪声抑制NS模块了。这里也再挖一坑,后面再根据WebRTC源码进行噪声抑制原理介绍。自动增益控制(Auto Gain Control)
在实际通话过程中,由于使用设备的差异和通话时离麦克风的远近,导致了通话的音量差异,为了达到统一的体验就需要进行自动增益控制,简单说就是当音量小时调大增益,当音量大时调小增益,达到减少音量起伏的作用。混音(Mix)
在多人通话场景下,我们需要接收和播放的通常不止一条音频流,但通常只有一个播放设备,因此通常需要对多条音频流先进行混音操作,再进行播放。
音频传输
目前WebRTC音频传输是UDP/RTP/RTCP协议基础上进行传输的,底层UDP协议的不可靠性,导致丢包不可避免,同时音频数据与其它的数据内容有其特殊性,通常一点音频异常都很容易被人感知出来。因此WebRTC针对音频传输做了很多额外的工作,除了最常见的丢包重传,丢包补偿等,还有一个NetEQ模块,会在播放端进行音频播放的加减速来进一步减少由于网络抖动引起的音频异常。
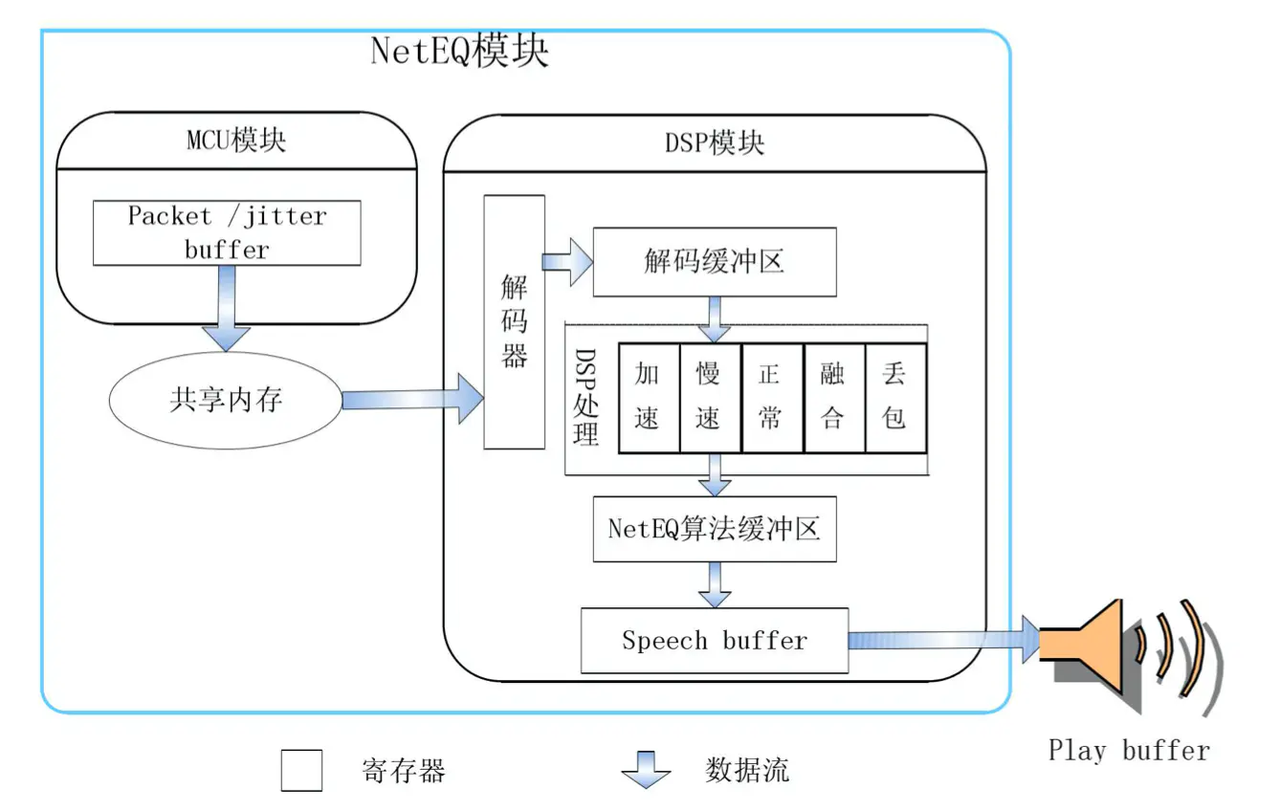
到这里WebRTC中跟音频相关的技术模块都简单的过了一遍,这样大家对于WebRTC音频处理有个大概的印象,这里的每个模块值得深入去学习,后面也把自己学习的一些心得记录在这里,大家一起学习呀。